Handling Skewed Data in Distributed Systems
The Power of Salting, Bucketing and Adaptive Query Execution

Data skew is a common issue in distributed systems that can severely impact the performance of data processing jobs. When data is not evenly distributed across partitions, some nodes in the cluster become overloaded while others remain underutilised. This imbalance leads to increased processing times and resource inefficiency. In this blog post, I will try to explore two effective techniques to mitigate data skew: salting and bucketing.
Understanding Data Skew
Data skew occurs when the distribution of data across partitions is uneven. For example, if a single partition holds a large portion of the data, it will take significantly longer to process than other partitions, leading to a bottleneck.
The Experiment Setup
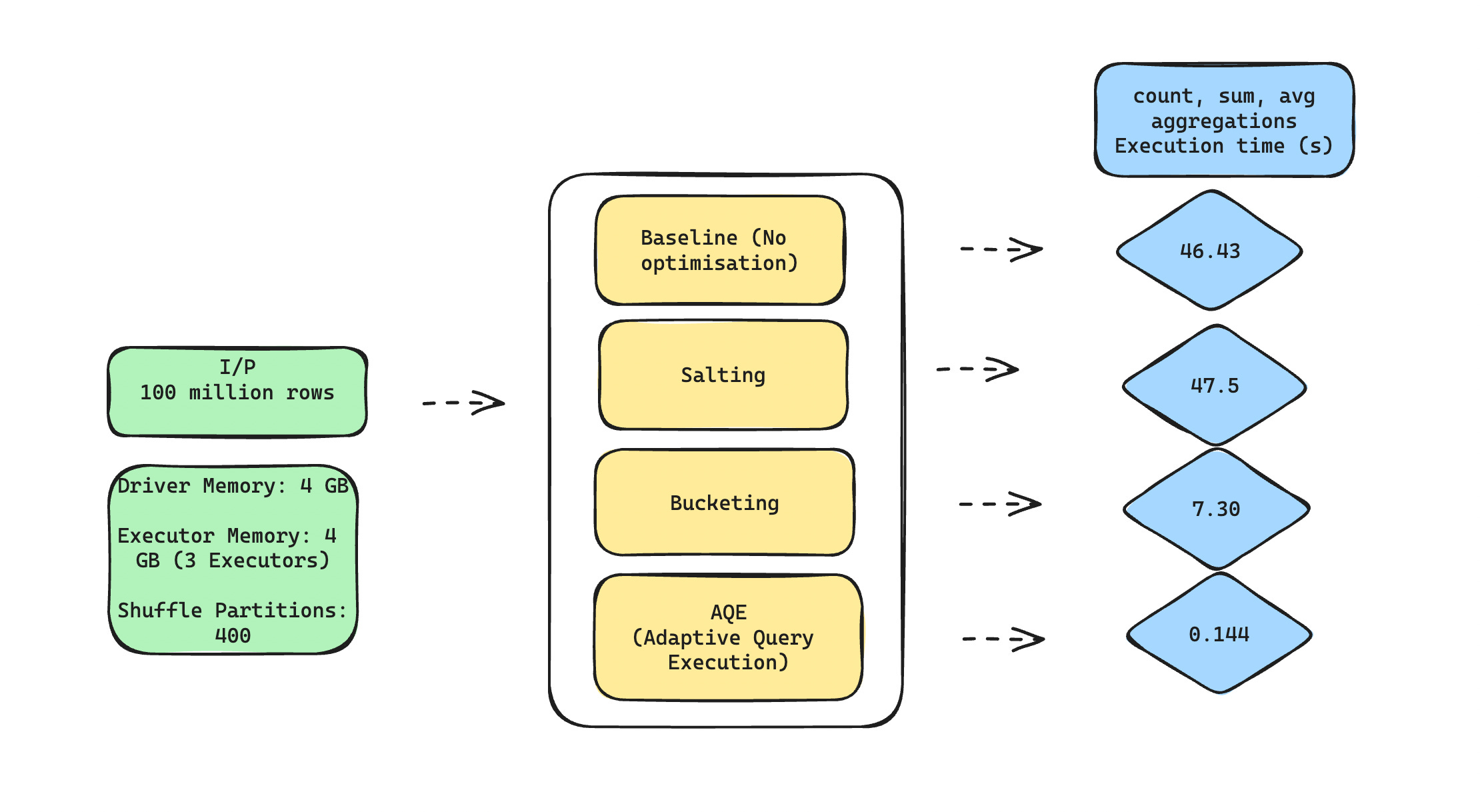
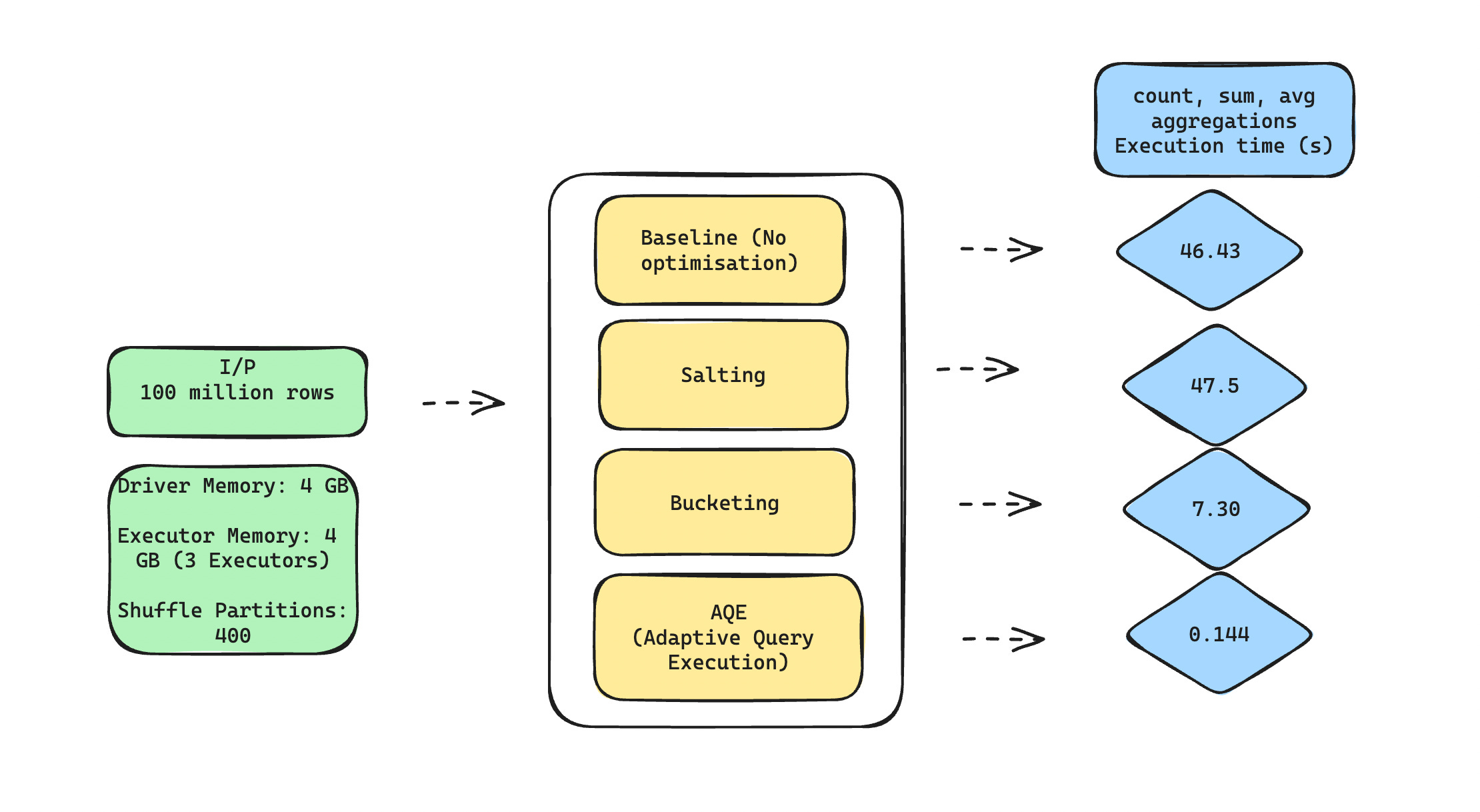
For our experiments, I used a Spark cluster configured with the following resources:
Driver Memory: 4 GB
Executor Memory: 4 GB (3 Executors)
Shuffle Partitions: 400
I ran the experiments on a large, manually simulated skewed dataset (100 million rows). The dataset consists of multiple records with significant skew in the `id` column.
Skewness Statistics:
Column: id, Skewness: -4.1296117184675145
Column: value, Skewness: 5.774025463480825E-5
id column skewness: The high negative skewness value indicates significant left skewness, meaning there are more frequent larger values on the left side of the distribution.
value column skewness: The near-zero skewness value indicates that the
valuecolumn distribution is almost symmetric, meaning there is no significant skewness.
Techniques to Handle Skewed Data
Without Any Skew Handling
Salting
Bucketing
Adaptive Query Execution (AQE)
1. Without Any Skew Handling
In this approach, we perform aggregations without any special techniques to handle skewness. This serves as our baseline for performance comparison. We also temporarily disable Adaptive Query Execution Plan for this scenario to be able to compare / benchmark with the Actual AQE scenario performance in later stages.
python
# Spark Job Without Salting (and without AQE)
def without_salting(df):
# Temporarily disable AQE for this operation
spark.conf.set("spark.sql.adaptive.enabled", "false")
result = df.groupBy("id").agg(
count("value").alias("count_value"),
avg("value").alias("avg_value"),
sum("value").alias("sum_value")
).orderBy(col("count_value").desc())
# Re-enable AQE
spark.conf.set("spark.sql.adaptive.enabled", "true")
return result
start_time = time.time()
result_no_salt = without_salting(df)
result_no_salt.persist(StorageLevel.MEMORY_AND_DISK)
result_no_salt.show()
time_no_salt = time.time() - start_time
print("Without Salting: --- %s seconds ---" % time_no_salt)2. Salting
Salting involves adding a random value (salt) to the keys to distribute them more evenly across partitions.
# Function to add salt to the keys
def add_salt(df, salt_factor=200): # Use a moderate salt factor
salted_df = df.withColumn("salted_id", concat_ws("_", col("id"), (col("id") % salt_factor)))
return salted_df
# Aggregation With Salting
def with_salting(df):
salted_df = add_salt(df)
salted_result = salted_df.groupBy("salted_id").agg(
count("value").alias("count_value"),
avg("value").alias("avg_value"),
sum("value").alias("sum_value")
).orderBy(col("count_value").desc())
return salted_result
start_time = time.time()
result_with_salt = with_salting(df)
result_with_salt.persist(StorageLevel.MEMORY_AND_DISK)
result_with_salt.show()
time_with_salt = time.time() - start_time
print("With Salting: --- %s seconds ---" % time_with_salt)
3. Bucketing
Bucketing distributes the data based on the hash value of the key. This helps in achieving better data distribution and reduces the need for shuffling during joins and aggregations.
# Aggregation With Bucketing
def with_bucketing(df):
result = df.groupBy("id").agg(
count("value").alias("count_value"),
avg("value").alias("avg_value"),
sum("value").alias("sum_value")
).orderBy(col("count_value").desc())
return result
# Write data to bucketed table
df.write.bucketBy(100, "id").sortBy("id").saveAsTable("exp_bucketed_table")
# Read from bucketed table
bucketed_df = spark.table("exp_bucketed_table")
start_time = time.time()
result_with_bucketing = with_bucketing(bucketed_df)
result_with_bucketing.persist(StorageLevel.MEMORY_AND_DISK)
result_with_bucketing.show()
time_with_bucketing = time.time() - start_time
print("With Bucketing: --- %s seconds ---" % time_with_bucketing)
4. Adaptive Query Execution (AQE)
AQE dynamically adjusts the execution plan based on the runtime statistics collected during query execution. It can optimize joins and reduce skewness by dynamically coalescing partitions.
# Aggregation With AQE
def with_aqe(df):
result = df.groupBy("id").agg(
count("value").alias("count_value"),
avg("value").alias("avg_value"),
sum("value").alias("sum_value")
).orderBy(col("count_value").desc())
return result
start_time = time.time()
result_with_aqe = with_aqe(df)
result_with_aqe.persist(StorageLevel.MEMORY_AND_DISK)
result_with_aqe.show()
time_with_aqe = time.time() - start_time
print("With AQE: --- %s seconds ---" % time_with_aqe)
Results
Here are the results of our experiments:
Technique | Time Taken (seconds)
Without Salting 46.43
With Salting | 47.50
With Bucketing | 7.30
With AQE | 0.144
Conclusion
Our experiments demonstrate that Adaptive Query Execution (AQE) offers the most significant performance improvement when dealing with skewed data. Here’s a detailed analysis of why AQE outperforms other techniques:
Dynamic Optimization: AQE dynamically adjusts the execution plan based on the runtime statistics. This means it can optimize the query execution path as the data is being processed, leading to more efficient handling of data skewness.
Automatic Handling of Skew: AQE automatically detects and handles skew in the data by coalescing partitions, adjusting shuffle partitions, and optimizing join strategies. This reduces the need for manual intervention and tuning, making it a highly efficient solution.
Resource Utilization: AQE ensures better utilization of cluster resources by dynamically adjusting the workload distribution across partitions. This leads to more balanced execution and faster query completion times.
Ease of Use: Unlike salting and bucketing, which require manual configuration and management, AQE works out-of-the-box with minimal setup. This simplicity, combined with its powerful optimization capabilities, makes it a preferred choice for handling skewed data.
By leveraging these techniques, especially AQE, you can efficiently handle data skewness in distributed systems and achieve better performance in your data processing tasks.